はじめに
二分探索は、探索範囲を半分ずつ絞りながら正解データを特定するアルゴリズムです。
下記のような問題に使用できます。
【例題】
小さい順に並べられているN個のデータA=[A1 ~AN]があります。要素XはAの何番目に存在するかを出力してください。
全探索でも解けますが、二分探索で実装してみます。
こちらが二分探索を用いた解法です。
#include <iostream> #include <vector> using namespace std; int BinarySearch(vector<int> a, int x, int n) { int L = 1; int R = n; int M = 0; while (L <= R) { M = (L + R) / 2; if (a[M] == x) return M; if (a[M] < x) L = M + 1; if (a[M] > x) R = M - 1; } return NULL; } int main(){ int N = 0; int X = 0; int ans = 0; cin >> N >> X; int offset = 1; vector<int> A(N + offset, 0); for (int i = 1; i <= N; i++) cin >> A[i]; ans = BinarySearch(A, X, N); if (ans == NULL) cout << "No" << endl; else cout << ans << endl; return 0; }
二分探索が可能となる条件
二分探索を行うための条件は下記です。
・配列が小さい順になっている。
そのため、小さい順になっていない配列に対して二分探索を行う場合は、配列を小さい順に整列するソートを行う必要があります。
二分探索のアルゴリズム
探索範囲を半減させる。
配列の中央にあたる値と探索している値の大小関係を確認し、探索範囲を半減させていきます。
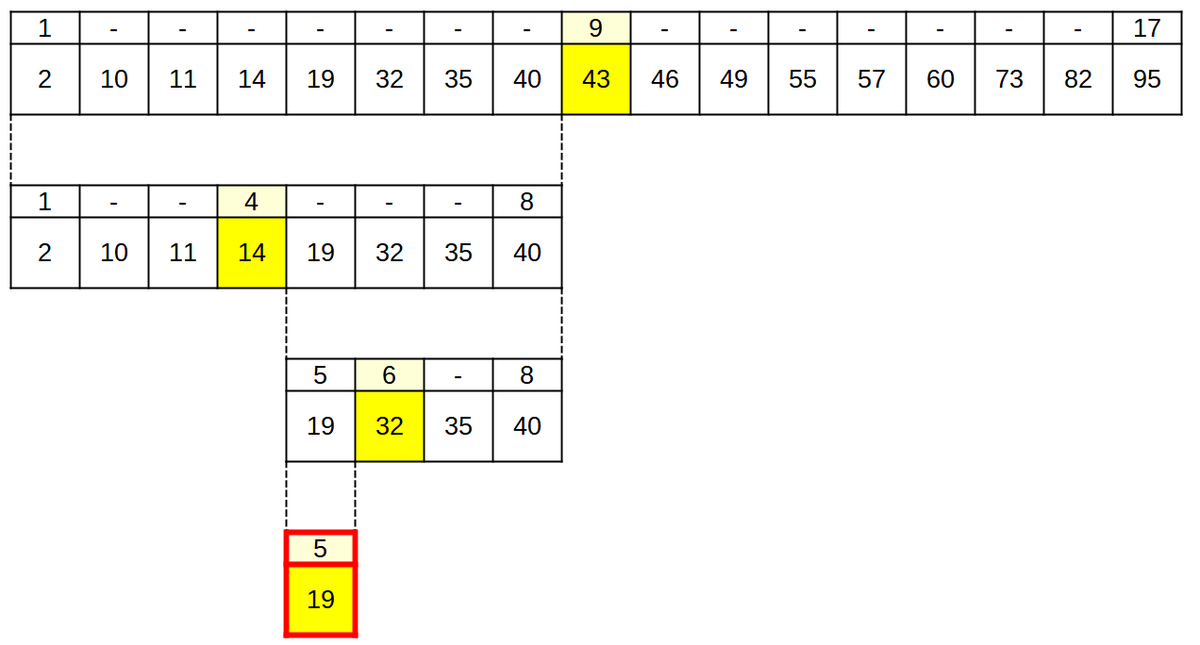
要素数17の配列から19を探索する流れを下記に示します。
1巡目では、インデックス番号9が真ん中の中央にあたるため、そこに格納されている値と探索している値の大小関係を比較します。結果、探索している値のほうが小さいので、インデックス番号1~8のどこかに格納されていることがわかります。
2巡目、3巡目でも同じ処理を行い、探索範囲を半分に絞り続けます。
4巡目の探索で、配列の5番目に19が格納されていることがわかりました。
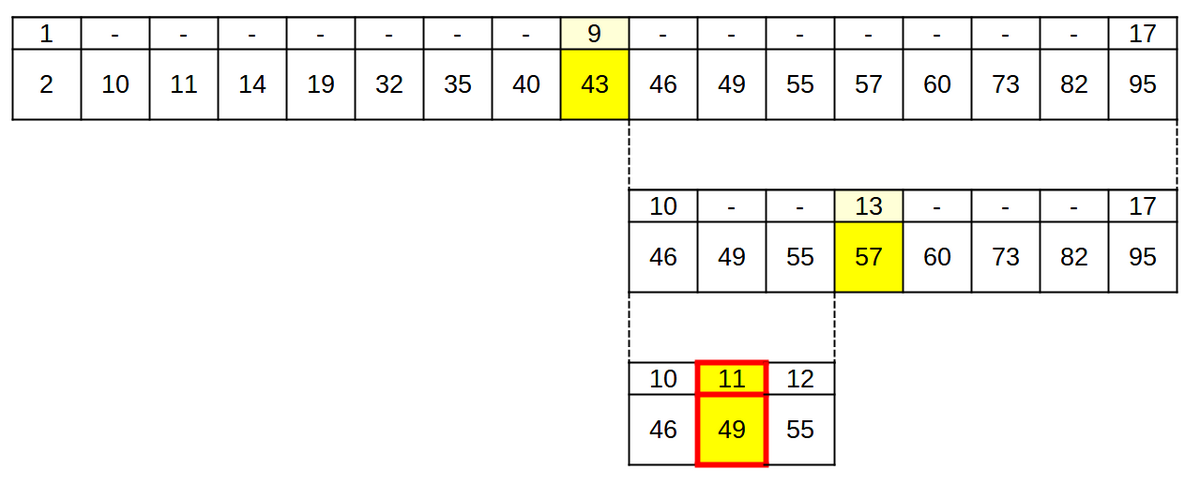
49を探索した場合を下記に示します。探索範囲の中央の値が探索している値だった場合、その時点で探索完了となります。
二分探索を実装する。
二分探索を実装していきます。例題を再度提示します。
【例題】
小さい順に並べられているN個のデータA=[A1 ~AN]があります。要素XはAの何番目に存在するかを出力してください。
データ数N, 探索したい値X, 配列の値Aを入力していきます。
int N = 0;
int X = 0;
int ans = 0;
cin >> N >> X;
int offset = 1;
vector<int> A(N + offset, 0);
for (int i = 1; i <= N; i++)
cin >> A[i];
入力した値を、二分探索を行う関数に引数として渡します。
ans = BinarySearch(A, X, N);
二分探索の関数の中身です。L,R,Mはインデックス番号の値が格納されます。
L:探索範囲のインデックス番号 最小値
R:探索範囲のインデックス番号 最大値
M:探索範囲のインデックス番号 中央値
int BinarySearch(vector<int> a, int x, int n) { int L = 1; int R = n; int M = 0; while (L <= R) { M = (L + R) / 2; if (a[M] == x) return M; if (a[M] < x) L = M + 1; if (a[M] > x) R = M - 1; } return NULL; }
中央値については、
M = (L + R)/2
で算出されます。探索範囲のデータ数が偶数だった場合、中央値の算出は切り捨てになります。
値が見つかればMの値を返します。
値が見つからなかった場合、Lの値がRを上回るため、ループから抜けるかたちとなり、NULL値を返します。
while (L <= R) { M = (L + R) / 2; if (a[M] == x) return M; if (a[M] < x) L = M + 1; if (a[M] > x) R = M - 1; } return NULL;
探索完了後の処理です。探索していた値が見つからなければNoを出力します。
ans = BinarySearch(A, X, N); if (ans == NULL) cout << "No" << endl; else cout << ans << endl;
全体のコードは以下です。
#include <iostream> #include <vector> using namespace std; int BinarySearch(vector<int> a, int x, int n) { int L = 1; int R = n; int M = 0; while (L <= R) { M = (L + R) / 2; if (a[M] == x) return M; if (a[M] < x) L = M + 1; if (a[M] > x) R = M - 1; } return NULL; } int main(){ int N = 0; int X = 0; int ans = 0; cin >> N >> X; int offset = 1; vector<int> A(N + offset, 0); for (int i = 1; i <= N; i++) cin >> A[i]; ans = BinarySearch(A, X, N); if (ans == NULL) cout << "No" << endl; else cout << ans << endl; return 0; }
二分探索の応用例
二分探索の応用例をいくつか示します。
X以下の最大値
【例題】 小さい順に並べられているN個のデータA=[A1 ~AN]があります。要素X以下の最大値にあたるAの値を出力してください。
#include <iostream> #include <vector> using namespace std; int BinarySearch(vector<int> a, int x, int n) { int L = 1; int R = n; int M = 0; while (L <= R) { M = (L + R) / 2; if (a[M] == x) return M; if (a[M] < x) L = M + 1; if (a[M] > x) R = M - 1; } return R; } int main(){ int N = 0; int X = 0; int ans = 0; cin >> N >> X; int offset = 1; vector<int> A(N + offset, 0); A[0] = NULL; for (int i = 1; i <= N; i++) cin >> A[i]; ans = BinarySearch(A, X, N); if (ans == NULL) cout << "No" << endl; else cout << A[ans] << endl; return 0; }
X以上の最小値
【例題】 小さい順に並べられているN個のデータA=[A1 ~AN]があります。要素X以上の最小値にあたるAの値を出力してください。
#include <iostream> #include <vector> using namespace std; int BinarySearch(vector<int> a, int x, int n) { int L = 1; int R = n; int M = 0; while (L <= R) { M = (L + R) / 2; if (a[M] == x) return M; if (a[M] < x) L = M + 1; if (a[M] > x) R = M - 1; } if (L > n) return NULL; else return L; } int main(){ int N = 0; int X = 0; int ans = 0; cin >> N >> X; int offset = 1; vector<int> A(N + offset, 0); for (int i = 1; i <= N; i++) cin >> A[i]; ans = BinarySearch(A, X, N); if (ans == NULL) cout << "No" << endl; else cout << A[ans] << endl; return 0; }
単調増加の関数
【例題】
正の整数Nが与えられます。N=x3を満たす正の実数xを出力してください。ただし、絶対誤差が0.001以下であれば正解とします。
探索対象のデータが他の要素に対して強い正の相関関係であれば、二分探索を用いることで正解データを特定できます。
#include <iostream> using namespace std; double Function(double x) { return x * x * x; } int main(){ double N = 0; double x_H = 1000000000; double x_L = 0; double x_M = 0; double answer = 0; cin >> N; while (x_L < x_H) { x_M = (x_L + x_H) / 2; answer = Function(x_M); if (answer >= (N - 0.001) && answer <= (N + 0.001)) { cout << x_M << endl; break; } if (answer < N) x_L = x_M; if (answer > N) x_H = x_M; } return 0; }
まとめ
二分探索は、探索範囲を半分ずつ絞りながら正解データを特定するアルゴリズムです。 条件として、小さい順に並べられているデータが必要になります。 そのため応用例として、探索対象のデータが他の要素に対して強い正の相関関係であれば、二分探索を用いることで正解データを特定できます。